多模态智能评测新纪元:FysicsWorld如何撕开「全模态」理想与现实的裂缝
多模态大模型的演进轨迹清晰可辨。从早期视觉+语言的简单叠加,到视觉+音频+语言的被动拼接,再到今天全模态统一架构的野望,技术的每一步跃迁都在重塑我们对人工智能的认知边界。然而,当学术界沉浸在模型架构的创新狂欢中时,一个根本性问题始终悬而未决:谁来评测这些模型的真实能力?
评测体系的结构性缺失
传统多模态评测长期困于三重桎梏。其一,模态覆盖的局限性——多数基准仍以文本为中心,对图像、视频、音频的整合停留在浅层对应,无法触及真实物理世界跨感官信息融合的本质。其二,输出形式的单一性——评测任务几乎清一色要求文本输出,对多模态生成、语音驱动交互等面向真实场景的能力视而不见。其三,模态关联的脆弱性——现有数据集粗暴地将不同模态信息拼接排列,却忽视模态间的语义耦合与信息互补,导致模型可轻易通过「单模态捷径」规避跨模态融合的真实挑战。
这三重桎梏的直接后果是:评测结果无法反映模型在真实物理世界中的全模态耦合能力,研究者缺乏统一框架进行公平比较,而应用开发者更无从判断模型是否真正具备面向复杂环境的智能。
FysicsWorld的核心架构设计
飞捷科思与复旦CITLab联合推出的FysicsWorld,首次在架构层面回应了上述挑战。该基准构建了覆盖16大任务、上百类真实开放域场景的统一评测体系,支持图像、视频、音频与文本间的双向输入输出。更关键的是,FysicsWorld创新引入跨模态互补性筛选策略(CMCS),通过严格的模态依赖性验证机制——随机移除模态后观察模型性能变化——确保每个评测样本必须依赖多模态信息融合才能解决,从根本上封堵了「单模态捷径」的可能性。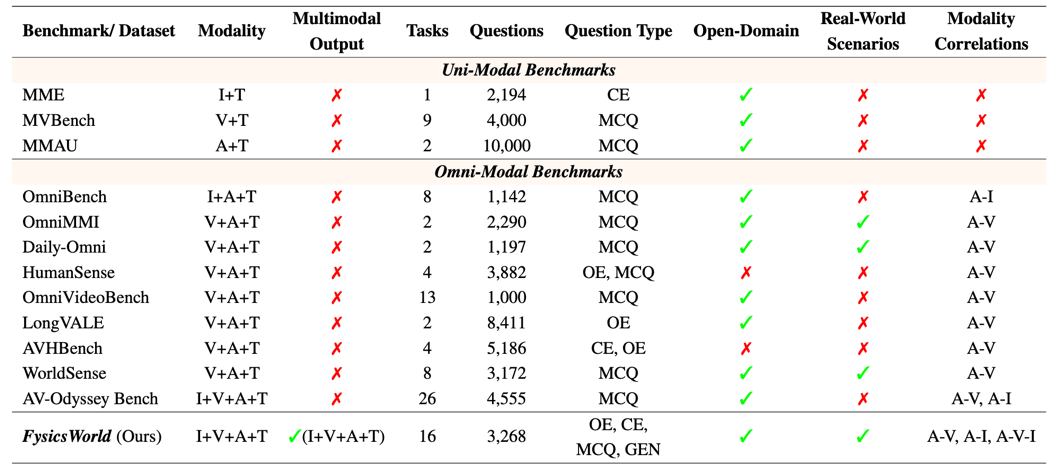
实证数据揭示的真相
基于FysicsWorld对30余个顶级模型的系统性评测揭示了一个冷酷事实:当前全模态模型在基础感知层面已展现竞争力,但在跨模态推理与人机交互任务中性能普遍大幅下滑。这尤其体现在语音驱动的视觉理解、基于视觉的音频合成、跨模态综合逻辑推断等必须依赖多模态真实互补关系的任务上。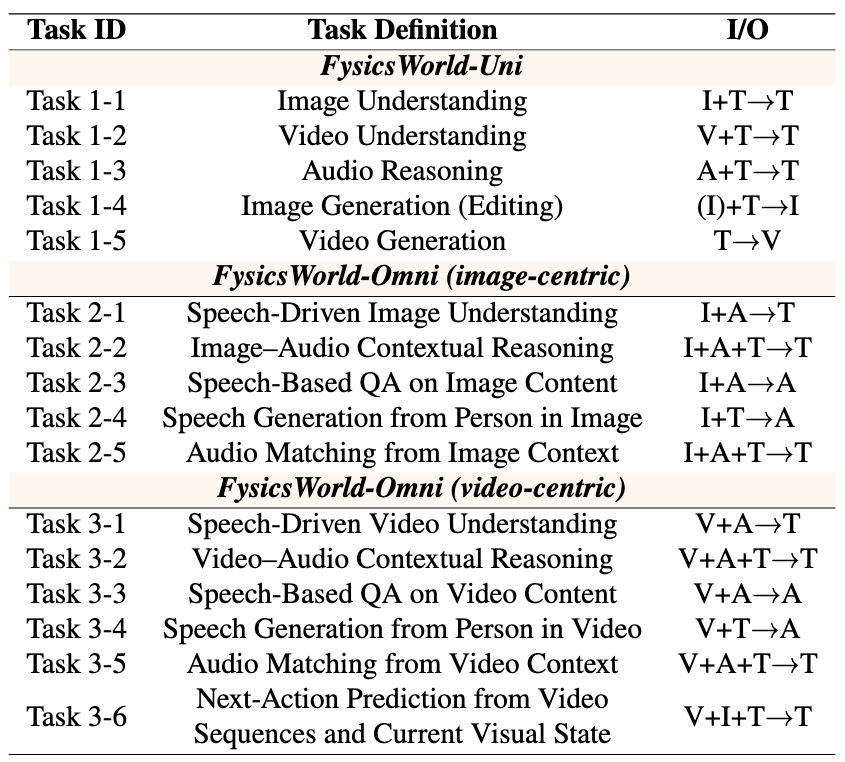
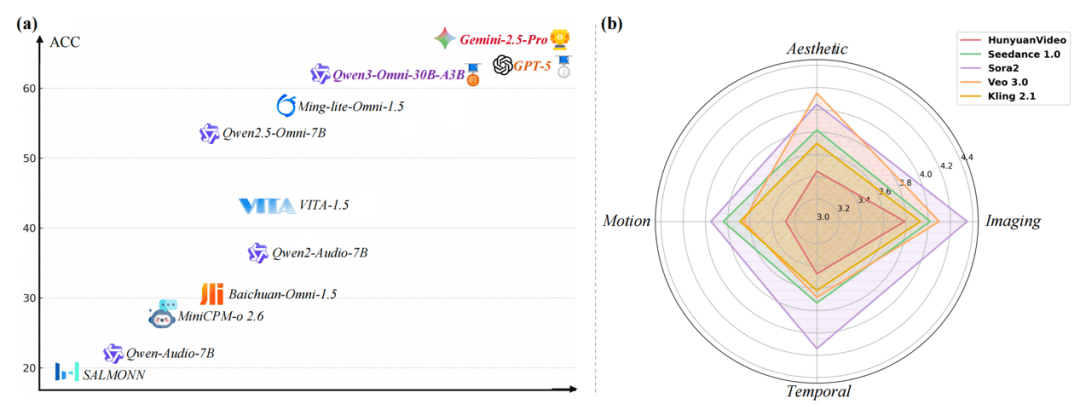
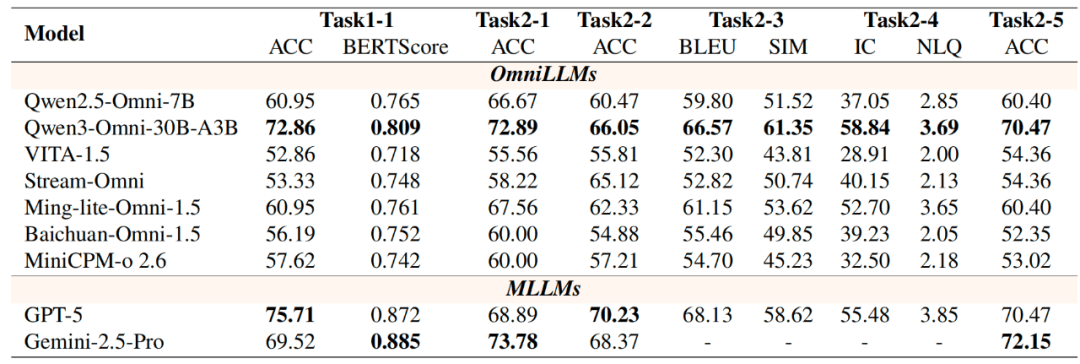
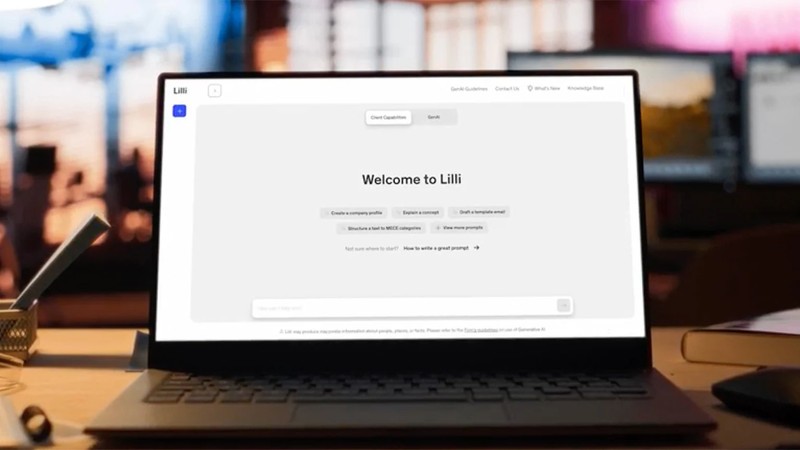
具体而言,GPT-5与Gemini-2.5-Pro在基础多模态任务中保持领先,但开源全模态模型在长视频语义链路、复杂听觉理解等环节仍存明显短板。而当评测转向真实物理场景时,所有模型都暴露出跨模态对齐、信息融合、物理场景适应能力的系统性不足。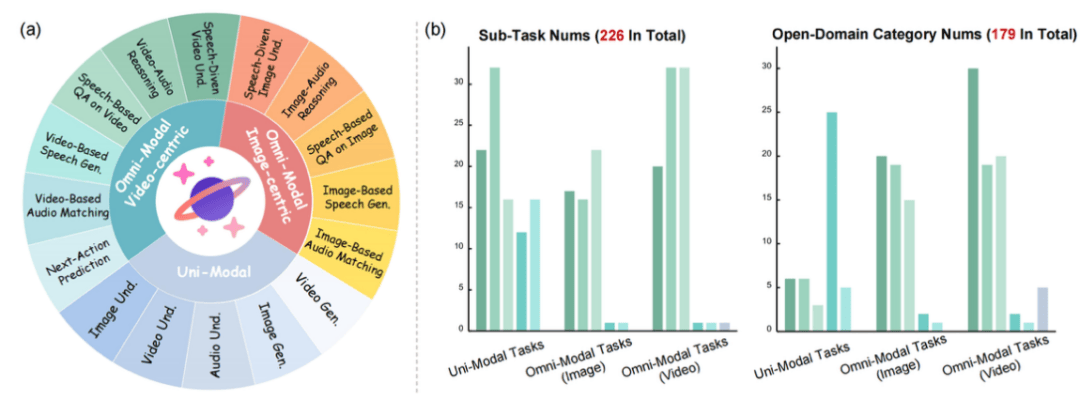
技术启示与演进方向
FysicsWorld的评测结果为下一代全模态模型指明了攻坚方向。首先,单模态能力的根基仍需持续巩固——视觉、听觉、语言在真实场景中的精度与一致性远未触达天花板。其次,模态融合策略需要系统性重构,实现多模态信息在时空、语义及物理约束维度的深度协调。跨模态动态推理与场景化理解将成为衡量模型核心竞争力的关键指标。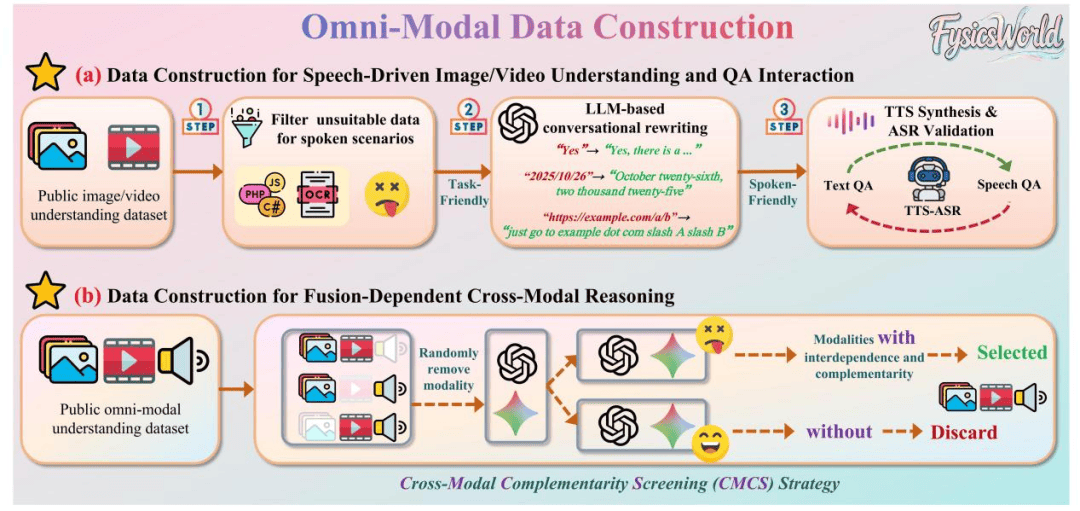
作为首个支持全模态输入输出、覆盖感知-理解-推理-生成全链路、并具备强跨模态依赖性的统一评测基准,FysicsWorld为研究者提供了可控、系统且可比较的能力映射工具。在其推动下,全模态智能正在从「多模态拼接」的理想迈向真正的统一智能。